

















Yahoo have just released TensorFlowOnSpark (TFoS), its latest framework for distributed deep learning on big-data clusters, to the open source community.
Nearly a year ago, Yahoo published CaffeOnSpark (CoS), an open source framework that allows distributed deep learning and big-data processing on identical Spark and Hadoop clusters. Yahoo uses CoS in many forms, and the framework has since been enhanced as a result of contributions from the community. However, it did not address the concerns of those using Google’s popular TensorFlow (TF), which was limited by its inability to be deployed on existing big-data clusters.
Yahoo developed TFoS to enable distributed TF execution on Spark and Hadoop clusters. Using a simple CLI and API, the new framework supports all types of TF programs, direct tensor communication among TF processes, scalable training of Inception image classification networks, and more.
Some initiatives have been noticed in the PHP community to expose tensorflow capabilities to PHP such as Tensile, however it’s still an experimental tool at its very early stages. PHP developers can simply implement a gRPC client for PHP that connect to tenserflow serving project to be able to talk to Tensorflow serving environment.
Below the press release :
Yahoo open-sources TensorFlowOnSpark, new distributed deep learning framework
February 15, 2017 – Yahoo has announced TensorFlowOnSpark, its latest open source framework for distributed deep learning on big-data clusters.
Deep learning (DL) has evolved significantly in recent years. At Yahoo, we’ve found that in order to gain insight from massive amounts of data, we need to deploy distributed deep learning. Existing DL frameworks often require us to set up separate clusters for deep learning, forcing us to create multiple programs for a machine learning pipeline (see Figure 1 below). Having separate clusters requires us to transfer large datasets between them, introducing unwanted system complexity and end-to-end learning latency.
Last year Yahoo addressed scaleout issues by developing and publishing CaffeOnSpark, our open source framework that allows distributed deep learning and big-data processing on identical Spark and Hadoop clusters. We use CaffeOnSpark at Yahoo to improve our NSFW image detection, to automatically identify eSports game highlights from live-streamed videos, and more. With the community’s valuable feedback and contributions, CaffeOnSpark has been upgraded with LSTM support, a new data layer, training and test interleaving, a Python API, and deployment on docker containers. This has been great for our Caffe users, but what about those who use the deep learning framework TensorFlow? We’re taking a page from our own playbook and doing for TensorFlow for what we did for Caffe.
After TensorFlow’s initial publication, Google released an enhanced TensorFlow with distributed deep learning capabilities in April 2016. In October 2016, TensorFlow introduced HDFS support. Outside of the Google cloud, however, users still needed a dedicated cluster for TensorFlow applications. TensorFlow programs could not be deployed on existing big-data clusters, thus increasing the cost and latency for those who wanted to take advantage of this technology at scale.
To address this limitation, several community projects wired TensorFlow onto Spark clusters. SparkNet added the ability to launch TensorFlow networks in Spark executors. DataBricks proposed TensorFrame to manipulate Apache Spark’s DataFrames with TensorFlow programs. While these approaches are a step in the right direction, after examining their code, we learned we would be unable to get the TensorFlow processes to communicate with each other directly, we would not be able to implement asynchronous distributed learning, and we would have to expend significant effort to migrate existing TensorFlow programs.
TensorFlowOnSpark
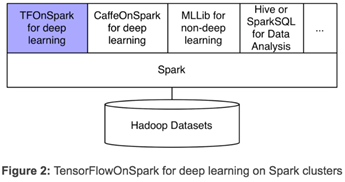
Yahoo’s new framework, TensorFlowOnSpark (TFoS), enables distributed TensorFlow execution on Spark and Hadoop clusters. As illustrated in Figure 2 above, TensorFlowOnSpark is designed to work along with SparkSQL, MLlib, and other Spark libraries in a single pipeline or program (e.g. Python notebook). TensorFlowOnSpark supports all types of TensorFlow programs, enabling both asynchronous and synchronous training and inferencing. It supports model parallelism and data parallelism, as well as TensorFlow tools such as TensorBoard on Spark clusters.
Any TensorFlow program can be easily modified to work with TensorFlowOnSpark. Typically, changing fewer than 10 lines of Python code are needed. Many developers at Yahoo who use TensorFlow have easily migrated TensorFlow programs for execution with TensorFlowOnSpark. TensorFlowOnSpark supports direct tensor communication among TensorFlow processes (workers and parameter servers). Process-to-process direct communication enables TensorFlowOnSpark programs to scale easily by adding machines. As illustrated in Figure 3, TensorFlowOnSpark doesn’t involve Spark drivers in tensor communication, and thus achieves similar scalability as stand-alone TensorFlow clusters.
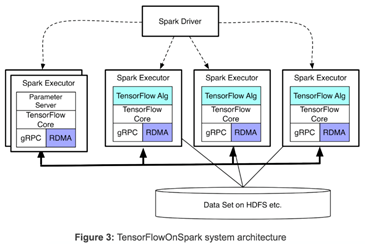
TensorFlowOnSpark provides two different modes to ingest data for training and inference:
- TensorFlow QueueRunners: TensorFlowOnSpark leverages TensorFlow’sfile readers and QueueRunners to read data directly from HDFS files. Spark is not involved in accessing data.
- Spark Feeding: Spark RDD data is fed to each Spark executor, which subsequently feeds the data into the TensorFlow graph viafeed_dict.
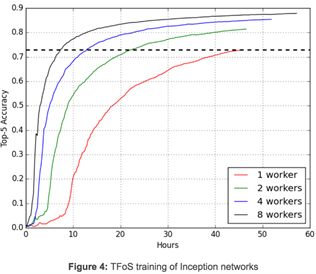
Figure 4 illustrates how the synchronous distributed training of Inception image classification network scales in TFoS using QueueRunners with a simple setting: 1 GPU, 1 reader, and batch size 32 for each worker. Four TFoS jobs were launched to train 100,000 steps. When these jobs completed after 2+ days, the top-5 accuracy of these jobs were 0.730, 0.814, 0.854, and 0.879. Reaching top-5 accuracy of 0.730 takes 46 hours for a 1-worker job, 22.5 hours for a 2-worker job, 13 hours for a 4-worker job, and 7.5 hours for an 8-worker job. TFoS thus achieves near linear scalability for Inception model training. This is very encouraging, although TFoS scalability will vary for different models and hyperparameters.
RDMA for Distributed TensorFlow
In Yahoo’s Hadoop clusters, GPU nodes are connected by both Ethernet and Infiniband. Infiniband provides faster connectivity and supports direct access to other servers’ memories over RDMA. Current TensorFlow releases, however, only support distributed learning using gRPC over Ethernet. To speed up distributed learning, we have enhanced the TensorFlow C++ layer to enable RDMA over Infiniband.
In conjunction with our TFoS release, we are introducing a new protocol for TensorFlow servers in addition to the default “grpc” protocol. Any distributed TensorFlow program can leverage our enhancement via specifying protocol=“grpc_rdma” in tf.train.ServerDef() or tf.train.Server().
With this new protocol, a RDMA rendezvous manager is created to ensure tensors are written directly into the memory of remote servers. We minimize the tensor buffer creation: Tensor buffers are allocated once at the beginning, and then reused across all training steps of a TensorFlow job. From our early experimentation with large models like the VGG-19 network, our RDMA implementation has demonstrated a significant speedup on training time compared with the existing gRPC implementation.
Since RDMA support is a highly requested capability (see TensorFlow issue #2916), we decided to make our current implementation available as an alpha release to the TensorFlow community. In the coming weeks, we will polish our RDMA implementation further, and share detailed benchmark results.
Simple CLI and API
TFoS programs are launched by the standard Apache Spark command, spark-submit. As illustrated below, users can specify the number of Spark executors, the number of GPUs per executor, and the number of parameter servers in the CLI. A user can also state whether they want to use TensorBoard (–tensorboard) and/or RDMA (–rdma).
TFoS provides a high-level Python API (illustrated in our sample Python notebook):
spark-submit –master ${MASTER} \
${TFoS_HOME}/examples/slim/train_image_classifier.py \
–model_name inception_v3 \
–train_dir hdfs://default/slim_train \
–dataset_dir hdfs://default/data/imagenet \
–dataset_name imagenet \
–dataset_split_name train \
–cluster_size ${NUM_EXEC} \
–num_gpus ${NUM_GPU} \
–num_ps_tasks ${NUM_PS} \
–sync_replicas \
–replicas_to_aggregate ${NUM_WORKERS} \
–tensorboard \
–rdma
- TFCluster.reserve() … construct a TensorFlow cluster from Spark executors
- TFCluster.start() … launch Tensorflow program on the executors
- TFCluster.train() or TFCluster.inference() … feed RDD data to TensorFlow processes
- TFCluster.shutdown() … shutdown Tensorflow execution on executors
Open Source
Yahoo is happy to release TensorFlowOnSpark at github.com/yahoo/TensorFlowOnSpark and a RDMA enhancement of TensorFlow at github.com/yahoo/tensorflow/tree/yahoo. Multiple example programs (including mnist, cifar10, inception, and VGG) are provided to illustrate the simple conversion process of TensorFlow programs to TensorFlowOnSpark, and leverage RDMA. An Amazon Machine Image is also available for applying TensorFlowOnSpark on AWS EC2.
Going forward, we will advance TensorFlowOnSpark as we continue to do with CaffeOnSpark. We welcome the community’s continued feedback and contributions to CaffeOnSpark, and are interested in thoughts on ways TensorFlowOnSpark can be enhanced.
About Yahoo
Yahoo is a guide to digital information discovery, focused on informing, connecting, and entertaining users through its search, communications, and digital content products. By creating highly personalized experiences, Yahoo helps users discover the information that matters most to them around the world — on mobile or desktop. Yahoo drives value for advertisers by helping them engage with consumers online through the combination of data, content and technology. Yahoo is headquartered in Sunnyvale, California, and has offices located throughout the Americas, Asia Pacific (APAC) and the Europe, Middle East and Africa (EMEA) regions. For more information, visit the pressroom (pressroom.yahoo.net) or the Company’s blog (yahoo.tumblr.com).
Yahoo and Yahoo Messenger is/are the trademarks and/or registered trademarks of Yahoo! Inc.
All other names are trademarks and/or registered trademarks of their respective owners.











{kind=link}